
























































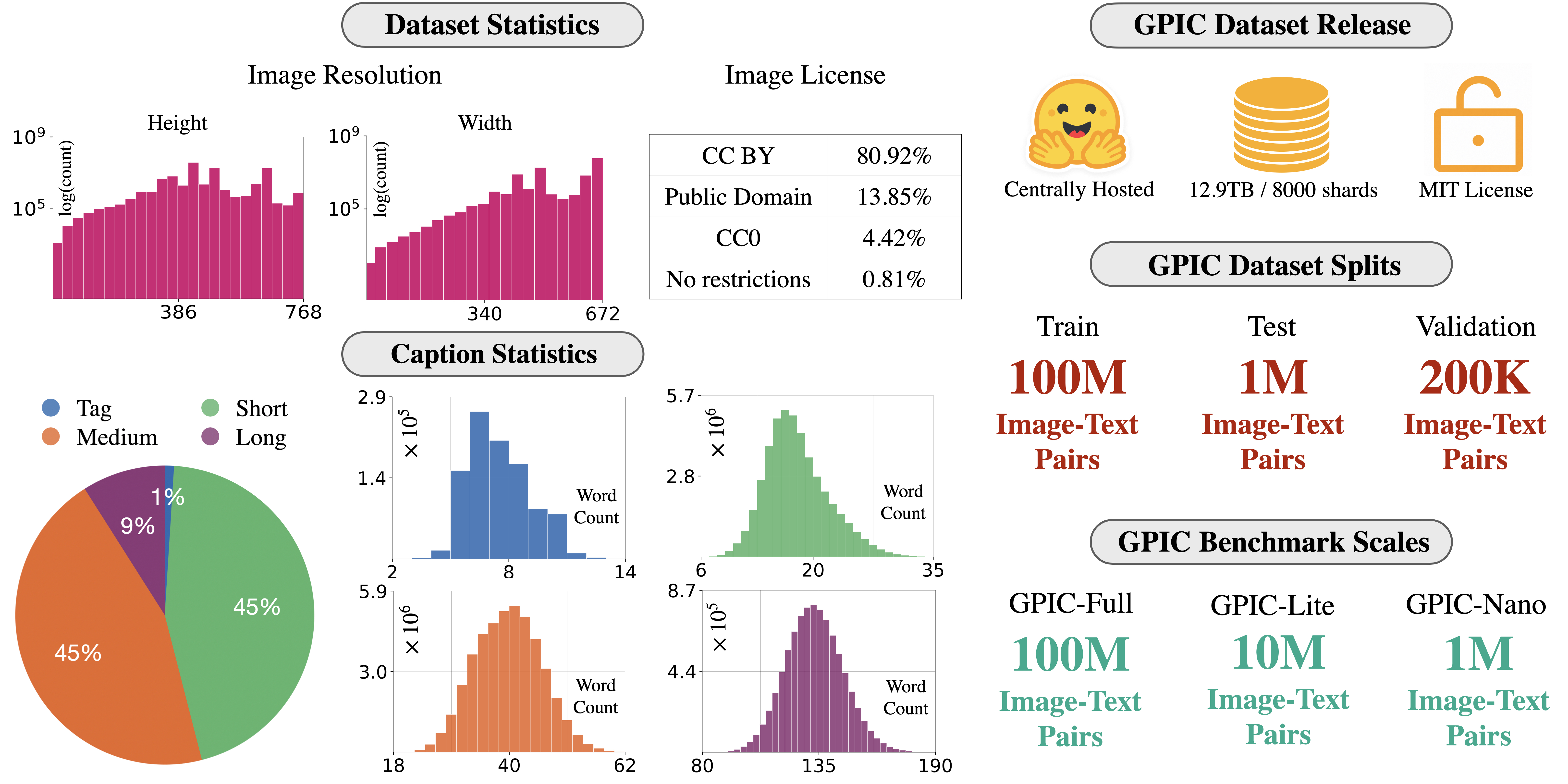
Studying scalable methods for visual generative modeling requires large, accessible, and stable datasets. We introduce GPIC, a Giant Permissive Image Corpus of approximately 28 trillion pixels. GPIC comprises diverse internet images captioned by a state-of-the-art vision-language model, including 100M training, 200K validation, and 1M test examples. Moreover, all GPIC images are permissively licensed for both research and commercial use. GPIC is safety-filtered, deduplicated, and centrally hosted on Hugging Face. We provide a benchmarking protocol for generative modeling on GPIC. Finally, we provide a reference baseline for pixel-space flow matching on GPIC. Our dataset, benchmark, and models are available on Hugging Face.
Click on a photo to see its caption.
@misc{chandrasegaran2026gpic,
title={GPIC: A Giant Permissive Image Corpus for Visual Generation},
author={Keshigeyan Chandrasegaran and Kyle Sargent and Suchir Agarwal and Michael Jang and Michael Poli and Juan Carlos Niebles and Justin Johnson and Jiajun Wu and Li Fei-Fei},
year={2026},
eprint={2605.30341},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.30341},
}We thank Radical Numerics and World Labs for providing compute for this project. We thank Willie Neiswanger, Yue Zhao, Armin W. Thomas, Garyk Brixi, Manling Li, Tristan Thrush, Wenlong Huang, Bailey Trang, and Aryaman Arora for their feedback on the manuscript. We thank Agrim Gupta for valuable discussions. We thank members of the Stanford Vision Lab and the CogAI group for their feedback.